Bray's "Five-Signature Acoustic Fingerprint" Analysis
Jon Aaron Bray (followtheepicenter.com) published an acoustic analysis claiming to locate a shooter position using TDOA multilateration across 6 camera recordings. The methodology sounds sophisticated — five acoustic signatures, GPS-verified camera positions, Strouhal frequency verification — but the foundation it's built on is fatally flawed.
SUMMARY
Bray's analysis synchronizes 6 camera recordings using manual frame picks, then performs TDOA multilateration to claim a shooter position at (106.98, 69.19) meters. Our evaluation demonstrates:
- ✗ Synchronization errors of 125–321 milliseconds — equivalent to 43–110 meters of spatial error
- ✗ Spatial errors are 4–5x larger than the entire camera array baseline (~25m)
- ✗ The shooter position is hardcoded as a constant in the script before the analysis runs
- ✗ Cameras producing inconsistent results are manually excluded without statistical justification
What Bray Claims
Bray claims to use a "five-signature acoustic fingerprint" method to locate a shooter in the case of State of Utah v. Tyler Robinson (September 10, 2025). Bray refers to this as the "UCCU Center" — the event actually took place at the UVU Fountain Courtyard, not the UCCU Center. The five signatures:
He claims all five signatures converge on a rooftop position at coordinates (106.98, 69.19) meters from a reference point, approximately 127 meters from the venue.
Problem 1 // Synchronization Failure
Every result in Bray's analysis depends on one thing: accurately synchronizing the 6 camera recordings to a common timeline. He does this by manually identifying a common visual event and noting the frame number in each video. This is the foundation — if the sync is wrong, everything built on top of it is meaningless.
Bray's EVENT_FRAMES
| Camera | Frame | FPS | Event Time |
|---|---|---|---|
| 13.mp4 | 252 | 30.00 | 8.400s |
| 2.MOV | 507 | 59.94 | 8.459s |
| 7.mp4 | 759 | 29.97 | 25.325s |
| 1.mp4 | 52 | 30.00 | 1.733s |
| IMG_6368.MOV | 55 | 29.97 | 1.835s |
| Video2_1.mp4 | 68 | 30.00 | 2.267s |
Note: event times range from 1.7s to 25.3s — these are raw file timestamps, not synchronized times. The sync offset is derived from these frame picks.
Testing the Sync: Cross-Correlation
To verify Bray's sync, we extracted audio from each video and cross-correlated overlapping pre-event audio between camera pairs. This is the gold standard — it compares actual shared ambient sound (voices, crowd noise) using FFT cross-correlation and is completely independent of any acoustic model or assumed source position. A Peak/RMS ratio above 10 confirms the audio genuinely overlaps.
CONFIRMED SYNC ERRORS
Only pairs with Peak/RMS > 10 have confirmed overlapping pre-event audio:
| Pair | XC Lag | Bray Offset | Sync Error | Spatial Error | Peak/RMS |
|---|---|---|---|---|---|
| Cam13 vs Cam2 | -66.8ms | +58.5ms | 125.3ms | 42.9m | 14.5 |
| Cam1 vs Cam6368 | -219.2ms | +101.8ms | 321.1ms | 110.1m | 12.1 |
Cam13 vs Cam2: Verified Across 8 Sliding Windows
The 125ms error is not a one-off measurement. Cross-correlation across the entire pre-event recording consistently reproduces the error with high confidence:
WHAT THIS MEANS
The sync errors are 4–5x larger than the entire camera array. Multilateration requires timing precision that's small relative to the camera baseline. With 125–321ms errors, the computed source positions are dominated by sync artifacts, not by actual acoustic propagation geometry. The results are not meaningful.
Visual Evidence // Waveforms
Audio extracted from all 6 cameras, aligned using Bray's EVENT_FRAMES sync. If the sync were accurate, the acoustic event transients would align at t=0.
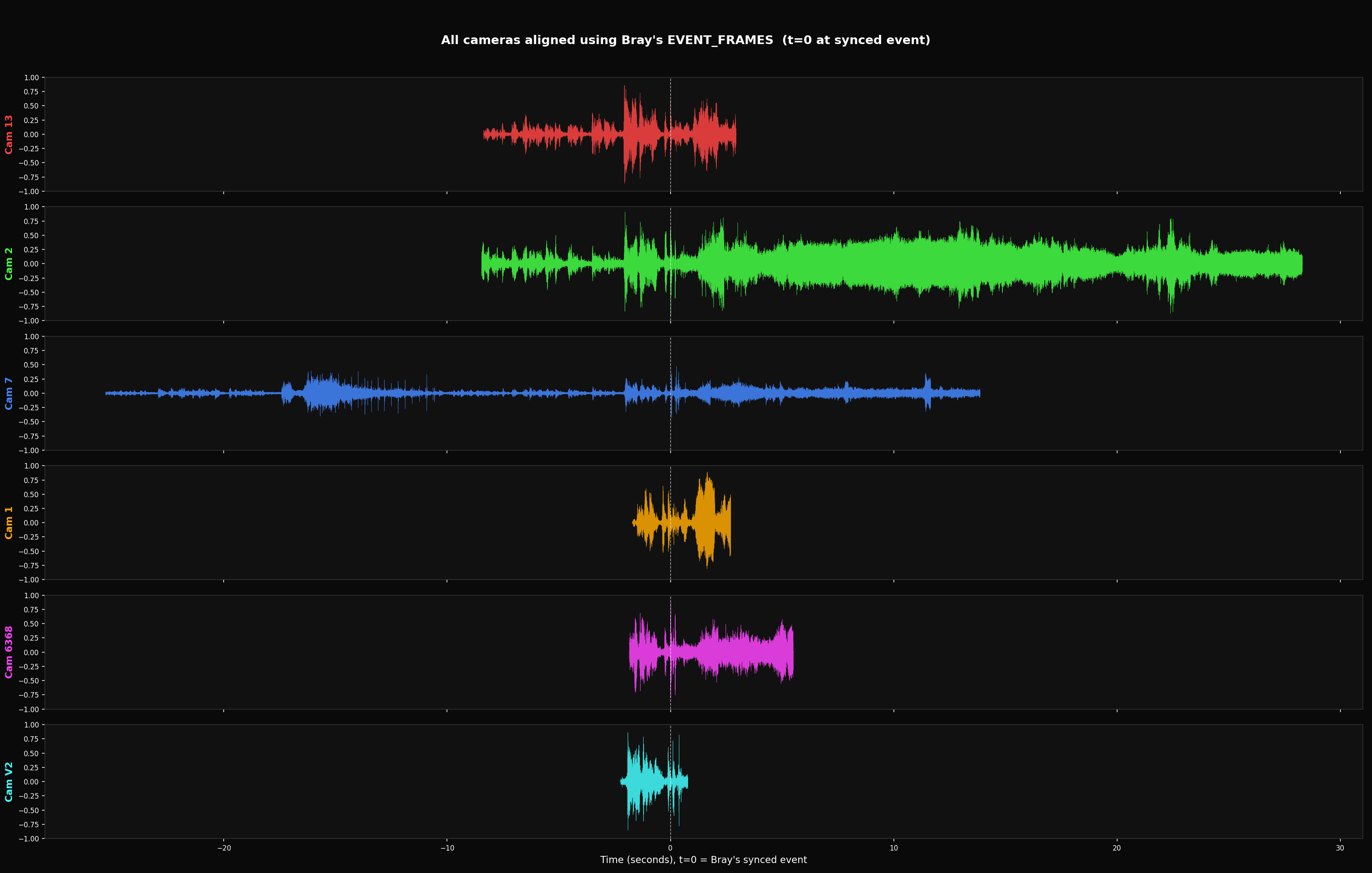
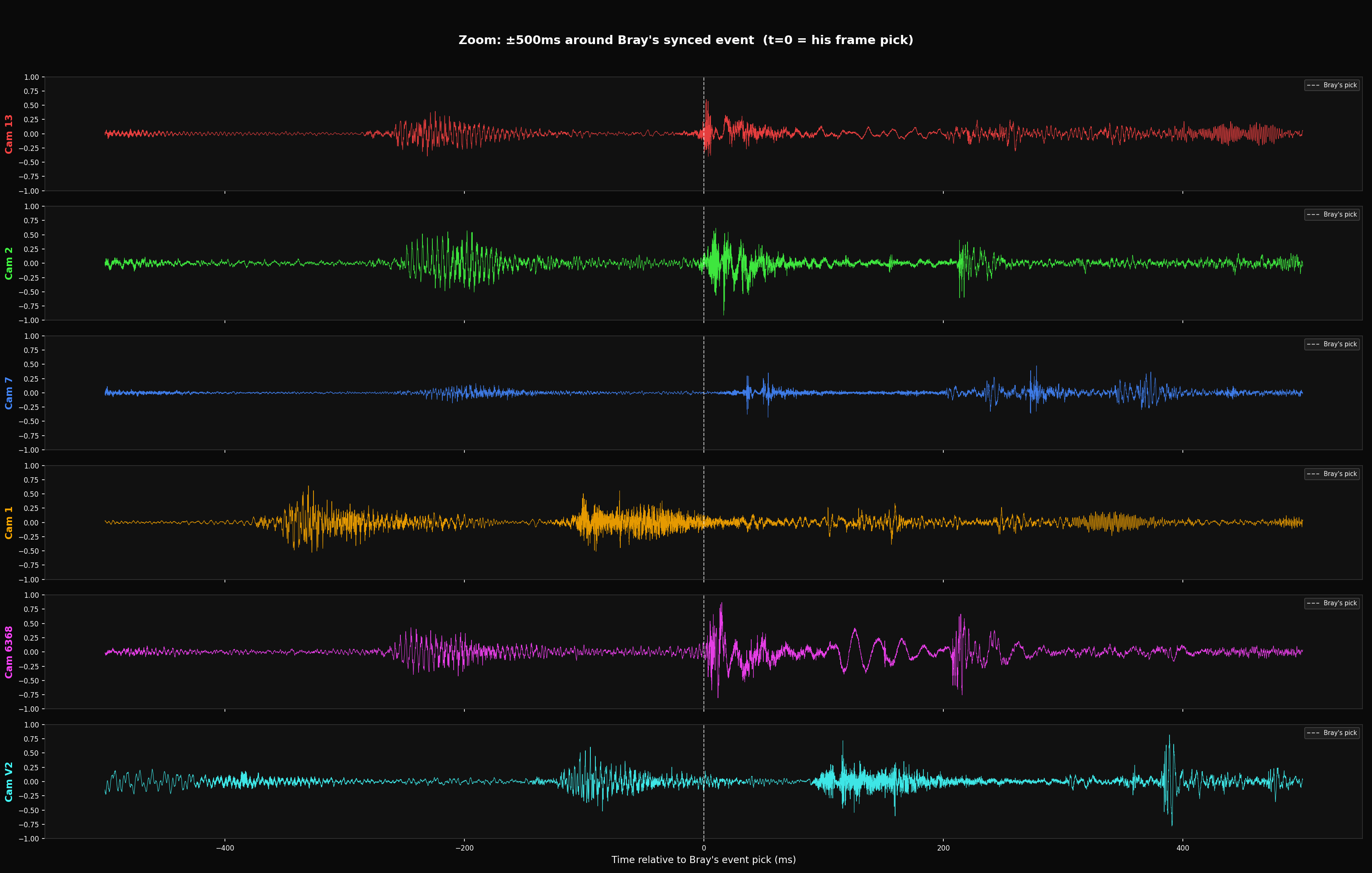
Problem 2 // Frame Resolution Floor
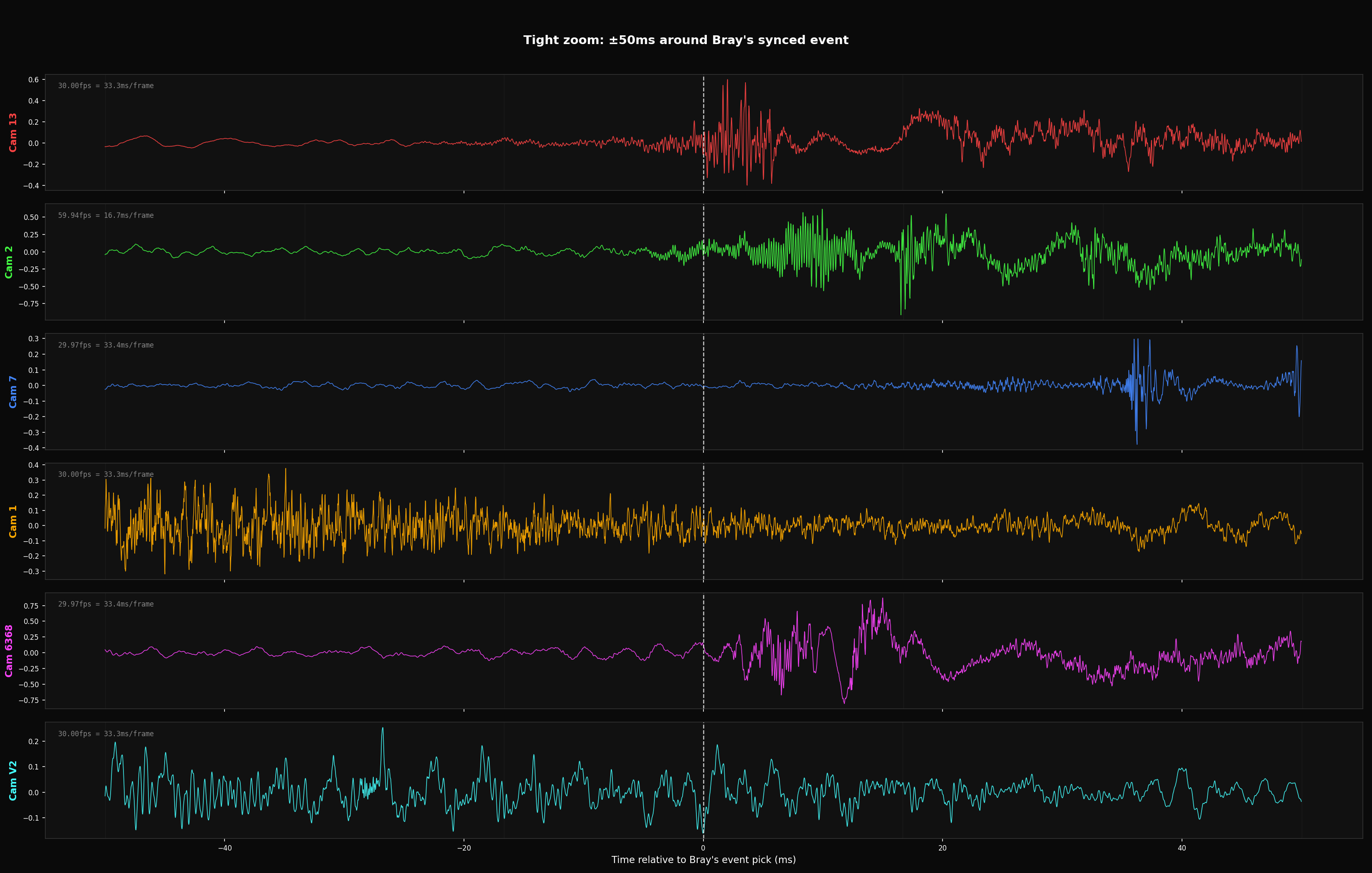
Even if Bray's frame picks were perfect, frame-based synchronization has an inherent precision limit of ±half a frame period. At 30fps, each frame spans 33.3ms — you can only know which frame the event is in, not where within that frame it occurs.
| Camera | FPS | Frame Period | Precision Floor | Spatial Floor |
|---|---|---|---|---|
| Most cameras | 30fps | 33.3ms | ±16.7ms | ±5.7m |
| Cam 2 | 59.94fps | 16.7ms | ±8.3ms | ±2.9m |
±5.7 meters of spatial uncertainty per camera — already comparable to the camera baseline distances. Audio-based cross-correlation sync is required for multilateration at these scales.
Problem 3 // Hardcoded Answer
Bray's script defines the shooter position as a constant before performing any analysis, then compares results against this predetermined answer.
This is circular reasoning:
- Define the answer as a constant
- Run the analysis
- Compare results to the predefined answer
- Claim the analysis "confirms" the position
The question that's never asked: does the solver actually converge on (106.98, 69.19) when given the real onset times without the hardcoded position? A modified version of the script with the hardcoded constant removed demonstrates that the TDOA solver is mathematically valid — given correct inputs, it recovers correct positions. The problem is that the inputs (sync times) are wrong, and the script never independently derives the position from the data.
Problem 4 // Manual Outlier Exclusion
Bray's script manually excludes cameras that produce inconsistent results:
if k not in ('1.mp4', 'Video2_1.mp4')}
No statistical justification is given for excluding these cameras. When data contradicts your hypothesis, you need a principled reason to discard it — not manual cherry-picking. Proper outlier detection uses statistical thresholds (e.g., sigma-based) applied uniformly to all data points.
Conclusions
The central failure of this analysis is the synchronization method itself. Manually picking video frames is not how forensic acoustic synchronization is conducted. In established forensic acoustic methodology, multi-source recordings are synchronized using audio-domain cross-correlation — matching shared ambient sound (crowd noise, PA systems, environmental audio) between overlapping recordings to achieve sub-millisecond alignment. This is a standard, well-documented technique in the field. Bray's frame-picking approach bypasses it entirely.
- 1 The synchronization method is wrong. Forensic acoustic analysis synchronizes recordings via audio cross-correlation of shared ambient sound — not by visually picking video frames. Frame-based sync has an inherent precision floor of ±16.7ms at 30fps (±5.7 meters), which alone approaches the camera baseline. When we applied the correct method (FFT cross-correlation of pre-event audio), we measured actual sync errors of 125–321ms — orders of magnitude worse than what TDOA multilateration requires.
- 2 The spatial errors are larger than the measurement array. At 343 m/s, 125ms of sync error translates to 42.9 meters of spatial uncertainty. 321ms translates to 110.1 meters. The entire camera baseline is approximately 25 meters. The errors are 4–5x larger than the array itself — the multilateration is solving for geometry that doesn't exist in the data.
- 3 The analysis is structured to confirm a predetermined conclusion. The shooter position is defined as a constant before the analysis runs. Cameras producing inconsistent results are manually excluded. The script never asks "where does the data say the source is?" — it only asks "does the data agree with the position I already defined?" This is not forensic analysis; it is confirmation bias encoded in Python.
- 4 None of the downstream results are recoverable. Every output of this analysis — onset times, TDOA calculations, multilateration solutions, the "five-signature" convergence — is built on the flawed sync. Correcting the sync doesn't fix the analysis; it invalidates it. The entire chain of results must be discarded and the analysis must be redone using proper audio-domain synchronization.
Update // Script Rewrite
After this analysis was published, Bray released a rewritten version of
acoustic_fingerprint_analysis.py —
significantly expanded from ~330 to ~900 lines with professional documentation, CLI arguments,
JSON output, diagnostic plots, and statistical metrics (SNR, sigma-above-noise).
Several of the most visible problems were removed:
- ✓ Removed the hardcoded outlier exclusion (
if k not in ('1.mp4', 'Video2_1.mp4')) - ✓ Removed the blatant circular Strouhal calculation from output
- ✓ Removed the "cavitation collapse detection" step
- ✓ Added statistical veneer (SNR, sigma calculations) to 4940Hz analysis
What didn't change — every methodological problem identified above:
- ✗ Shooter position still hardcoded:
SHOOTER_POSITION = np.array([106.98, 69.19])(renamed fromSHOOTER) - ✗ Same EVENT_FRAMES — same frame picks, same frame-based synchronization
- ✗ No audio cross-correlation sync implemented — still uses manual frame picking
- ✗ Same onset detection, same multilateration solver, same results compared to predetermined position
The rewrite makes the script look more professional. It does not fix any of the problems that make the results unreliable.
All analysis was performed using publicly available recordings and Bray's published script. The cross-correlation methodology, evaluation code, and raw results are documented and reproducible. Sync evaluation used FFmpeg for audio extraction (mono, 48kHz, 16-bit PCM) and FFT-based cross-correlation with Peak/RMS confidence metrics.